Stay in the loop
$3M in research grants //
Rolling acceptances open
Funding the next wave of frontier benchmarks
In partnership with
Benchmarks that define and advance the frontier
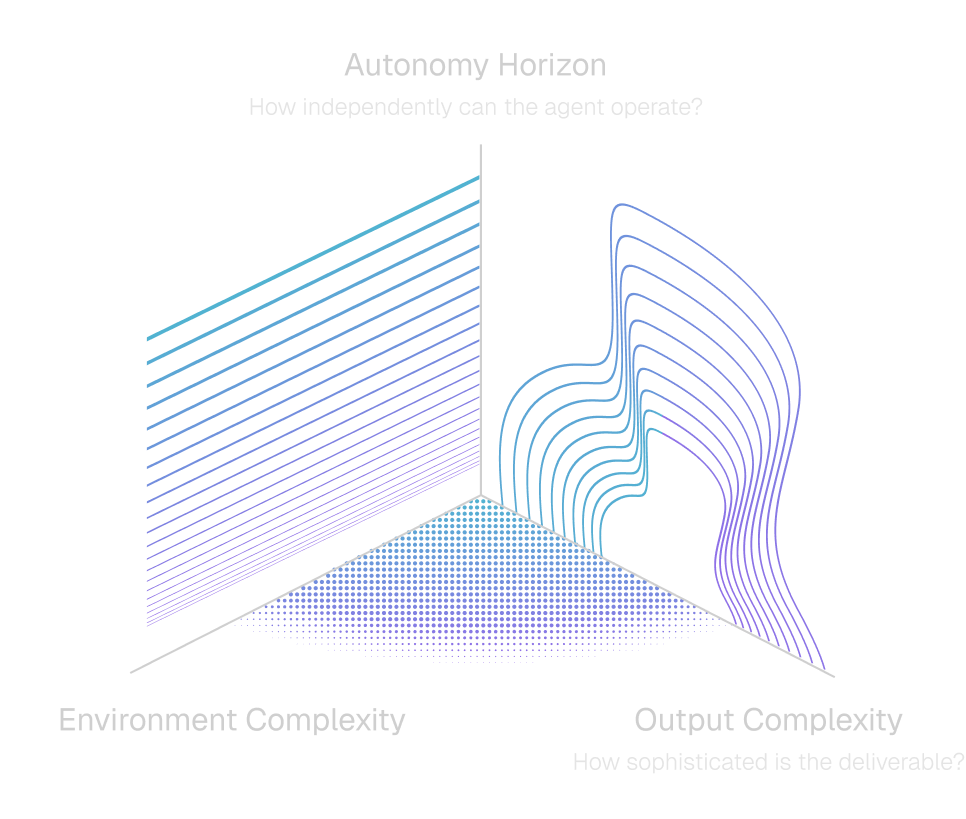
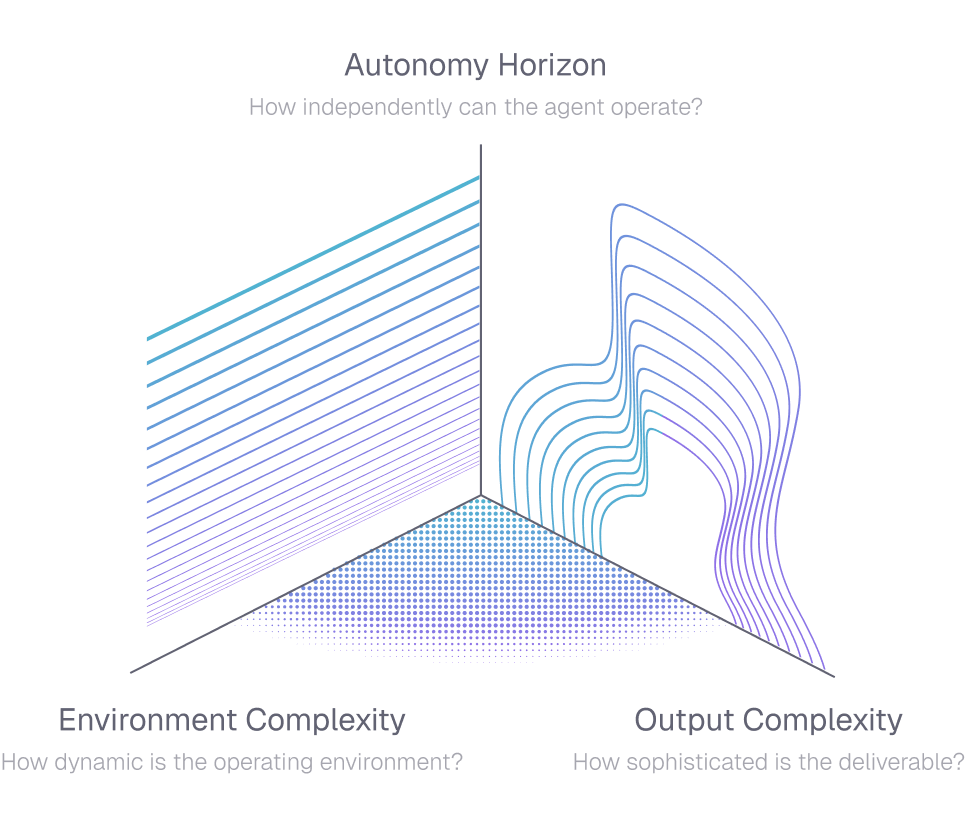
Our ability to measure AI has been outpaced by our ability to develop it, and this evaluation gap is one of the most important problems in AI. Looking ahead, Benchmarks must close the gap between what we measure and actually encounter, falling along three core dimensions: environment complexity, autonomy horizon, and output complexity.
Backed by a $3M commitment, the Open Benchmarks Grants program funds open-source datasets, benchmarks, and evaluation artifacts that shape how frontier AI systems are built and evaluated.
Read the blog
Featured benchmarks
Continual Learning Bench
A benchmark of expert-validated, difficult tasks for agents that learn and improve across sequences of task instances, instead of static systems that complete independent tasks.
UC Berkeley SkyLab, UW-Madison, Snorkel AI
Agent's Last Exam
The largest-scale, broadest-coverage agent evaluation benchmark to date, measuring performance on long-horizon, economically valuable tasks with verifiable outcomes.
UC Berkeley RDI, RDI Foundation, Snorkel AI
SlopCode Bench
A community benchmark measuring code erosion as agents iteratively extend their own solutions across checkpoints.
UW-Madison, DARPA, National Science Foundation, Snorkel AI
Terminal-Bench 2.0
89 high-quality tasks across software engineering, machine learning, security, data science, and more.
Stanford, Laude Institute, Harbor, Snorkel AI
More on the horizon
Stay updated on new benchmarks
We're building benchmarks across new domains and modalities. Drop your email and we'll let you know when the next one ships.

Call for proposals
We are seeking applications from researchers, labs, and engineers building benchmarks for the next wave of AI capabilities. We’re looking for benchmarks that drive the fundamental axes for AI agency (read more on our blog) and welcome independent directions from the research community as well.
Apply for a grant
How to apply
01
Apply
Submit a brief application for the Open Benchmarks Grant. Applications are reviewed on a rolling basis.
02
Selection
Proposals are reviewed with input from a steering committee of academic and industry leaders.
03
Launch
Selected teams receive expert data credits and begin collaboration with Snorkel, partner research teams, and platform partners where applicable.
04
Publication
Recipients create and publish the resulting open-source dataset or paper, with acknowledgment of Snorkel’s support.
Rolling acceptances — no fixed deadline. Apply when you're ready.
Steering committee
Proposals are reviewed by a committee of researchers and engineers at the frontier of AI evaluation. They bring independent academic judgment — Snorkel does not direct their decisions.

Karthik Narasimhan
Princeton University
Professor of Computer Science at Princeton. Research focuses on reinforcement learning for language and agentic systems.

Chris Ré
Stanford University
Associate Professor at Stanford and co-founder of Snorkel AI. Pioneered programmatic data development for machine learning.

Ludwig Schmidt
Stanford University · LAION
Stanford researcher and LAION collaborator. Co-creator of CIFAR-10.1, WILDS, and several foundational evaluation benchmarks.

Yu Su
Ohio State University
Professor at Ohio State. Research spans conversational AI, question answering, and evaluation methodology for language models.

Lewis Tunstall
Hugging Face
Machine learning engineer at Hugging Face and co-author of Natural Language Processing with Transformers.

Fred Sala
Univ. of Wisconsin–Madison
Assistant Professor at Wisconsin–Madison. Research focuses on data-centric AI, weak supervision, and programmable training pipelines.