Stay in the loop
Closing the Evaluation Gap in Agentic AI
Announcing a $3M commitment to launch Open Benchmarks Grants
Published: February 11, 2026

Today, AI is marked by a growing asymmetry: the excitement around agentic AI is real—backed by quantitative progress on model cards and genuine leaps forward, especially in coding. But ask individuals or enterprises where they feel ready to deploy agentic automation in high-stakes, domain-specific settings outside of coding… and you will find hesitation. The reason: our ability to measure AI has been outpaced by our ability to develop it, and this evaluation gap is one of the most important problems in AI.
The evaluation gap won’t be solved by public benchmarks alone, and the risk of “benchmaxxing” is real— closing it will also require use-case-specific field deployments and other evaluation tools. But benchmarks are a critical piece of the measurement toolkit; and the best open benchmarks don’t just measure AI progress—they define entire new vectors of AI development. Benchmarks like Terminal-Bench, METR, and ARC-AGI become critical guideposts for the field of AI—and the path to safe, trustworthy AI agents will depend on more of them.
Open benchmarks are one of the most important levers for advancing AI safely and responsibly—but the academic and open-source teams driving them often hit resource constraints, especially in the face of the exponentially expanding complexity of what tomorrow’s benchmarks need to cover. That’s why Snorkel, with support from our partners at Hugging Face, Prime Intellect, Together AI, Factory HQ, Harbor and PyTorch, is launching Open Benchmarks Grants: a $3M commitment to support the research and development of open benchmarks for AI.
Closing the AI evaluation gap with open benchmarks
Looking into the agentic future, benchmarks must close the gap between what we measure and actually encounter, falling along three core dimensions: environment complexity, autonomy horizon, and output complexity.
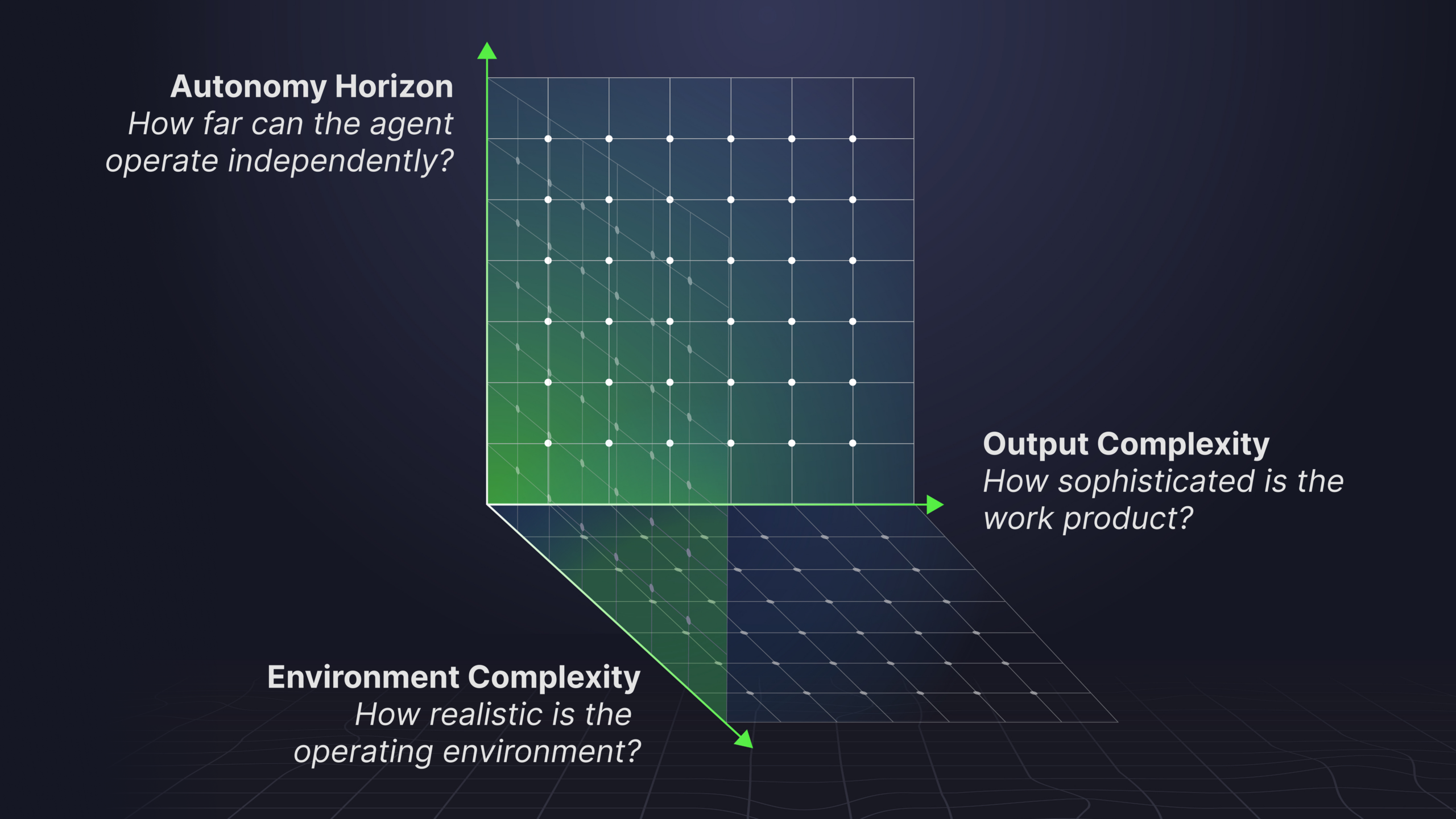
Environment complexity
Real operating environments are far more complex than today’s benchmark environments, and that gap is often where agents fail. For instance, consider coding agents, the most advanced agents today: a real codebase has org-specific policies, sprawling context across Slack screenshots and design docs, flaky toolchains, human reviewers with tribal knowledge, and parallel contributors. Most benchmarks capture a fraction of this complexity. Tomorrow’s benchmarks need to capture aspects of environment complexity like:
- Domain specificity: Real-world deployments require navigating domain-specific nuance, ranging from unwritten knowledge and constraints to specialized standards and terminology.
- Context complexity: In production settings, context is incredibly rich and noisy, pulling in use-case specific knowledge, documents, unstructured information, messy multi-persona input, feedback, and more.
- Multi-modality: Agents increasingly work across modalities beyond text, including image, video, and audio/voice, which reflect dimensions like spatial relationships, physical constraints, and temporal dynamics that text alone doesn’t capture.
- Tool complexity: Agents must operate in realistic action spaces and toolsets, e.g., selecting from large toolsets where each tool has constraints (e.g., rate limits, permissions), ambiguous or incomplete documentation, and/or outputs requiring interpretation/chaining.
- Human and multi-agent interaction: Agents don’t operate alone; they work alongside human collaborators and other agents. Benchmarks should test the full spectrum of coordination, from multi-turn dialogue with co-pilots to task division and handoffs across agents.
Autonomy horizon
A defining axis of autonomy is how long an agent can operate before reliability breaks down. Take a customer experience agent onboarding an enterprise customer over several weeks: by week two, it may lose track of the customer’s needs across hundreds of setup tasks; an early integration choice can introduce issues that won’t surface until launch; and a reorg can shift priorities midstream. Each of these reflects a distinct dimension:
- Long-horizon scope: Longer trajectories mean more opportunities for missteps and consequent failure. We need benchmarks that measure reliable operation over hundreds or thousands of steps, from maintaining goals to recovering from errors.
- World modeling: Agents will need to operate in environments where outcomes are expensive to explore and difficult to predict without an internal model of the world they operate in; we need benchmarks that test these settings.
- Non-stationary goals and environments: Goals evolve, requirements shift, and environments change. Agents must recognize and adapt to these changes rather than assume fixed conditions.
Output complexity
As agents produce more complex work, evaluation (both for final evaluation and reward signals during training) must become more complex too—and the gap is growing. For instance, consider an agent producing an entire software product, or a complex report making a strategic recommendation. There’s no unit test for whether a deliverable is “good or bad”; instead, nuanced rubrics and evaluations of many dimensions—and perhaps of the processes, research, and reasoning used to produce them—need to be considered in a use case specific way. Tomorrow’s benchmarks need to capture these aspects:
- Multi-faceted work products: Agent outputs have expanded from single answers to multi-artifact deliverables, e.g., codebases, documents, workflows, and we need to evaluate the entirety of these products.
- Nuanced, multi-factor rubrics and reward signals: As agents produce open-ended, multi-dimensional work, we need rubrics that go beyond “pass/fail” to assess quality across dimensions like correctness, clarity, depth, and usability—and ultimately, human uplift, not just task completion.
- Trustworthy outputs: Trusted autonomy demands better judgement. We need benchmarks that test whether agents calibrate for risk, surface uncertainty honestly, and recognize when the right action is to stop, refuse, or escalate.
Our $3M commitment to fund Open Benchmarks Grants

Selected teams will receive funding, scaled expert data development support, and/or research and engineering collaboration, drawing from a decade of data-centric AI research and deployments starting at the Stanford AI Lab. Our founding partners Hugging Face, Prime Intellect, Together AI, Factory HQ, Harbor and PyTorch are also contributing research, advisory support, and platform credits.
The path to trusted autonomy will require an honest and evolving view of what agents can and cannot do, shaping everything from the next generation of products to public policy decisions. The pioneers building new open benchmarks that define the major new vectors of development in AI are doing some of the most important work in AI—and we are incredibly excited to support them with Open Benchmarks Grants.
Applications are reviewed on a rolling basis starting March 1, 2026. Apply for a grant here. Selections will be made on a quarterly basis.
The Frontier Data Summit is coming this fall.
Interested in learning more?
Contact us for questions regarding the application process: benchmarks@snorkel.ai.